Здравствуйте! Данный материал размещен в рамках 4-го
конкурса, проводимого BotmasterLabs.
В этой статье будут продемонстрированы процессы поиска и сбора базы, обучение
неизвестных движков и постинг по базе. Надеюсь, что кому-то будет полезен
данный мануал.
Рынок программного обеспечения для продвижения сайтов растет
очень быстрыми темпами. Существует большое количество программ для рассылки по
базам. Этим мы и воспользуемся. Чтобы облегчить жизнь пользователям софта, разработчики
делают готовые шаблоны для комментирования гостевых, блогов, галерей, для
постинга в форумы, в вики и т.д. Так вот одним из таких шаблонов мы и
воспользуемся. Софт, у которого мы возьмем готовый шаблон, это GSA Search Engine Ranker. На просторах интернета полно аналогичного софта. Наверняка у вас есть похожий софт. Скачать
файл можно здесь.
Т.к. в шаблоне используются вариации, то нам потребуется
размножить текст. Открываем файл, в начале и в конце ставим двойные кавычки,
макрос “%image_title%” (без кавычек)
заменяем на * (звездочку). Копируем содержимое в буфер! Открываем в браузере
онлайн инструмент для размножения текста:

Вставляем содержимое из буфера. Настраиваем инструмент. В блоке
“Основные” выставляем кодировку windows-1251,
указываем количество вариантов (чем больше вариантов, тем больше будет база для
рассылки хрумером), выбираем случайную генерацию. В блоке “Дополнительно”
ставим галочки напротив “Удалить дубликаты” и “Перемешать результат”. В блоке
“Пост-обработка” снимите все галочки. Жмем кнопку “Генерировать”. Вы можете
воспользоваться каким-то другим аналогичным сервисом или софтом.
Полученный результат мы будем использовать в качестве
запросов для парсинга. Создаем в папке “Words” текстовый файл и вставляем туда полученный результат.
Открываем
Hrefer. Переходим Options – Parsing Options.

В блоке “Duplicates
filtering” поставьте галочку напротив "Enable filtering of duplicated
links by hostnames". В блоке “Duplicates filtering method” выберите
"By hostnames". В блоке “Query options” установите галочки напротив “Do not
use “Additive words”” и “Disable filtering harvested links by Sieve-filter”. В блоке “Query ordering” выберите "Words + Additive Words". Во вкладке “Words Database”
выберите нашу базу с запросами. Парсить лучше выдачу Google. Можете
воспользоваться методом парсинга поисковых систем, который я описал в первой статье.
Теперь база у нас есть! Теперь надо определить движки из
этой базы. А сделать это можно с помощью инструмента Хрумера: Анализатор
признаков ссылок.

Выбираете нашу напарсенную базу. В блоке “Область анализа”
выбираете “/path/filename”. В блоке “Формат
отчета” выбираете “Xrumer pattern”.
Установите галочки напротив “Экспортировать в файл отчета LinksReport.txt”, “Показать количество в тексте”, “Ограничение
в отчете на N
признаков”. Как видно на скриншоте в базе приемущественно движки галерей.
С помощью Google
можно определить какие именно это движки. Из этих движков Хрумер поддерживает DatsoGallery
("option=com_datsogallery"), ZenPhoto ("Photo Templates from
Stopdesign" "Image Info"), Plogger ("powered by
plogger" "Post a comment"). Хрумер пока не поддерживает 4image
("Powered by 4images" "Post comment"), Piwigo
("Powered by Piwigo" "Add a comment"), YaPig ("Powered
by YaPig" "Add your comment"), Shutter ("Submit a comment
for this photo" "View Slideshow"), Pixelpost ("Camera &
Exposure Information" "Leave a Comment"), Gallery
("main.php?g2_itemId="), Coppermine Photo Gallery ("Add your
comment" "Coppermine Photo Gallery"). На случай, если вы
соберетесь напарсить отдельно базы под каждый движок, в скобках я указал
признаки для запросов. Теперь нам нужно обучить Xrumer комментировать неизвестные
движки.
"Обучаем движку Gallery"
Я покажу на примере одного из них. Это Gallery ("main.php?g2_itemId="). Остальные
движки обучаются по аналогии. Я конечно обучил постить во все галереи. В конце
статьи приложу архив с модификацией.
Приступим! Открываем инструмент ModCreator. В адресной строке инструмента
вводим “http://www.frederickcastro.com/gallery2/main.php?g2_itemId=2480” (без
кавычек). Жмем зеленую стрелочку. Далее кликаем по ссылке с анкором “Add Comment”. Перед нами форма
для комментирования. Надо ознакомить хрумер с новыми полями.

Кликаем правой кнопкой мышки по полю “Name” и выбираем: Set Field – NICKNAME. Затем
жмем кнопку “Добавить” (с зеленым крестиком). Аналагичную процедуру производим
и с полями Subject, Comment и Captcha. В блоке "Результат"
жмем "Сохранить". Еще нам нужно обучить Xrumer скачивать изображение каптчи.
Поэтому открываем HTML-код
страницы (правый клик мышки и выбираем View HTML-code).

На скриншоте видна ссылка на изображение каптчи. Поэтому в
файл default.mask.txt из папки “ DeCaptcha” вставляем “[Include] [inLink]g2_view=captcha.CaptchaImage[/][/]” (без
кавычек).
Теперь переходим во вкладку xmessages.txt. Нам нужно написать комментарий и
узнать правило успеха для Хрумера. Значит заполняем поля Name, Subject, Comment,
Captcha и сохраняем
комментарий.

Перед нами появилось сообщение “Comment added successfully”. Вот его то мы
и будем использовать. В блоке “Обучение” напротив “Признак” вставляем “Comment added successfully” (без кавычек), а напротив “Значение” из выпадающего списка выбираем “SUCCESS”. Жмем
"Добавить".
Еще нам нужно узнать правило, указывающее Хрумеру, что
произошла ошибка при комментировании.
Для этого создаем искусственную ошибку при комментировании, т.е. не
заполняем одно из полей или неправильно вводим каптчу. Сайт нам выдаст ошибку.
 Открываем HTML-код
страницы и находим участок кода с ошибкой. В нашем случае я
выдрал несколько правил для хрумера: Your comment has not been saved, Incorrect
number, Incorrect letters. Далее в блоке “Обучение” напротив “Признак”
вставляем по очереди правила “Incorrect number”
и “Incorrect letters”,
а напротив “Значение” выбираем из списка PICTOTRY. Жмем
"Добавить". Потом в блоке “Обучение” напротив “Признак” вставляем “Your comment has not been saved”, а напротив “Значение”
выбираем из списка INVALID. Жмем
"Добавить". Затем в блоке
"Результат" жмем "Сохранить". Все процедуры с ModCreator завершены. Открываем
файл xurl.txt из папки LogicFiles.
Открываем HTML-код
страницы и находим участок кода с ошибкой. В нашем случае я
выдрал несколько правил для хрумера: Your comment has not been saved, Incorrect
number, Incorrect letters. Далее в блоке “Обучение” напротив “Признак”
вставляем по очереди правила “Incorrect number”
и “Incorrect letters”,
а напротив “Значение” выбираем из списка PICTOTRY. Жмем
"Добавить". Потом в блоке “Обучение” напротив “Признак” вставляем “Your comment has not been saved”, а напротив “Значение”
выбираем из списка INVALID. Жмем
"Добавить". Затем в блоке
"Результат" жмем "Сохранить". Все процедуры с ModCreator завершены. Открываем
файл xurl.txt из папки LogicFiles.

Вставляем туда: “AddLinkRule([0,'?g2_view=comment.AddComment&g2_itemId='],URL_TONEWPOST);” (без кавычек). Согласно
этому правилу Хрумер будет искать ссылку для комментирования.
Обучение завершено! Переходим к настройкам Хрумера и
созданию проекта.
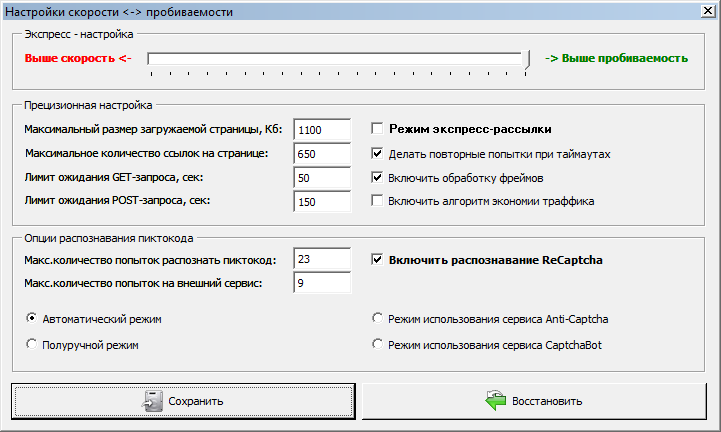
Переходим: Настройки – Скорость и Пробиваемость.

В блоке “Экспресс-настройка” переводим бегунок к “Выше
пробиваемость”. В блоке ”Прецизионная настройка” устанавливаем галочки
напротив: “Делать повторные попытки при таймаутах” и “Включить обработку
фреймов”. В блоке “Опции распознавания пиктокода” устанавливаем галочку
напротив “Включить распознавание ReCaptcha”. Укажите нужное вам количество
попыток распознания пиктокода. Выберите “Полуручной режим” или один из режимов
использования сервисов: Anti-Captcha или CaptchaBot.
Переходим: Настройки – Дополнительные настройки. Тут все по
дефолту. В блоке “Рассылка” устанавливаем галочки напротив “Входить под текущим
аккаунтом, если логин занят”, “Если не работает BB-код – трансформировать его в HTML”.

Переходим: Настройки – Активация профайлов по e-mail. Выбираем “Отключить”.

Создаем проект! Тут нас интересуют несколько полей: никнейм
(тут можете использовать анкор), домашняя страница, почта (тут можете
использовать фэйковую почту, т.к. активировать аккаунты нам не придется), тема
(тут можно использовать кейворды) и тело сообщения (тут можно использовать bbcode, если сайт не будет
поддерживать bbcode, то
программа автоматически конвертнет в html).

И не забываем использовать вариации или макрос #file_links. Все готово! Выбираем базу и
стартуем!
Если надоест вводить эти капчи вручную, и нет средств тратиться на сервис Антикапчи, можно просто попросить разработчика программы обучить её распознавать эти капчи на автомате - это будет сделано для вас бесплатно. XRumer автоматически распознаёт вот уже более 200 типов капч, в том числе РеКапчу и Яндекс-капчу, и с каждым месяцем этот набор пополняется (в последнем апдейте добавилось еще 25 типов капч).
Если надоест вводить эти капчи вручную, и нет средств тратиться на сервис Антикапчи, можно просто попросить разработчика программы обучить её распознавать эти капчи на автомате - это будет сделано для вас бесплатно. XRumer автоматически распознаёт вот уже более 200 типов капч, в том числе РеКапчу и Яндекс-капчу, и с каждым месяцем этот набор пополняется (в последнем апдейте добавилось еще 25 типов капч).
К статье прилагаю архив со всеми нужными файлами: измененные
файлы логики Хрумера, базу запросов для парсинга, базу для постинга. Всем спасибо за внимание!